Durch die rasante Entwicklung und Verbreitung mobiler Endgeräte, wie z.B. Smartphones, Tablets und Wearables, ist die Anzahl ortsbezogener Dienste enorm angestiegen. Viele Anwendungen ortsbezogener Dienste sind nicht mehr aus unserem Alltag wegzudenken. Sie sind Teil unseres Lebens geworden und beeinflussen unsere zukünftigen Entscheidungen und Verhaltensweisen. Dabei nutzen wir z.B. die Wetter-App am Morgen, um zu schauen ob wir den Regenschirm brauchen, schauen in die Verkehrsanbindungs-App, um den schnellsten Weg zur Arbeit zu finden, und informieren uns in der lokalen Nachrichten-App über aktuelle Themen. Überall begegnen uns Situationen, in denen wir diese Dienste aus Informationsbedarf oder Zeitvertreib immer wieder nutzen.

Dabei haben fast alle ortsbezogenen Dienste gemein, dass sie die aktuelle Position eines Nutzers sowie seine Aktivität zur Bereitstellung ihrer Dienste nutzen. Um die aktuelle Position oder gar die Aktivität eines Nutzers zu bestimmen, werden Sensordaten und Schnittstellen über das eigene mobile Endgerät verwendet. Dabei kommen funkbasierte Technologien wie GPS oder WLAN zum Einsatz. Trotzdem mangelt es immer noch an Verfahren zur Ortsbestimmung und Positionierung, die es erlauben, eine durchgehende Positionsbestimmung an allen Orten zu ermöglichen.
Motiviert durch die hohe Verbreitung von Kamerasensoren in Smartphones und Tablets sowie die gleichzeitig geringen Kosten, der autarken Funktionsweise und der rasanten Entwicklung im Bereich der Bildverarbeitung, ist der Einsatz visueller Verfahren zur Positionsbestimmung und Aktivitätserkennung erstrebenswert. Besonders durch die technologische Entwicklung und die Einführung einer ganz neuen Geräteklasse, der sogenannten Wearables, ist die Chance solche Verfahren weiter zu entwickeln immens gestiegen. So werden Geräte wie z.B. die Google Glass oder Microsoft Holo Lens bereits mit visuellen Verfahren betrieben, da sie grundsätzlich eine oder mehrere Kamerasensoren einsetzten, um die Lage der Kamera oder anderer Objekte im Raum zu bestimmen. Dadurch können Anwendungen der Augmented Reality realisiert werden, um z.B. virtuelle Objekte realitätsgetreu und in Echtzeit anzuzeigen.
Bereits heute werden zahlreiche Polizisten in den USA und auch in Deutschland mit sogenannten Bodycams ausgestattet, um einen vollständigen Polizeieinsatz überwachen zu können. Dabei lassen sich durch die aufgezeichneten Videosequenzen zahlreiche Informationen ableiten, um Sachverhalte rekonstruieren und besser verstehen zu können. Diese Informationen können in naher Zukunft bereits in Echtzeit analysiert und ausgewertet werden. Dadurch könnten Einsätze effizienter und sicherer gestaltet werden.
Allgemein lässt sich mit visuellen Sensoren, insbesondere durch die günstigen Kamerasensoren, eine Reihe von sinnvollen Verfahren zur Bestimmung der Position, der Lage, der Aktivität und des Kontextes realisieren.
Im Folgenden soll ein allgemeiner Einblick über Verfahren aus dem Bereich des maschinellen Sehens geben werden. Anschließend werden visuelle Verfahren für ortsbezogene Dienste vorgestellt, die im Rahmen der Promotion von Chadly Marouane unterstützend durch die Virality GmbH und die Ludwig-Maximilians-Universität entwickelt worden sind. Diese Verfahren nutzen die Videosequenz einer mobilen Kamera, die entweder von einer Person getragen oder an einer Person direkt befestigt wird. Anhand dieser Verfahren werden die aktuelle Position, die gegangene Trajektorie sowie die getätigten Aktivitäten einer Person bestimmt.
Verfahren aus dem Bereich des maschinellen Sehens
Das Gebiet des maschinellen Sehens ist ein stetig wachsendes Feld, welches in einem rasanten Tempo immer komplexere Systeme und Verfahren hervorbringt. Hinter jedem Verfahren und System steht eine meist einfache Kamera, die einzelne oder ganze Sequenzen von Bildern aufzeichnet. Um aus einem einzelnen Bild oder einer Sequenz Informationen ableiten zu können, muss man wissen welche Informationen aus einem Bild verwendet und wie man diese Informationen möglichst vollständig und automatisiert extrahiert. Dafür muss zunächst eine geeignete Bildrepräsentation gefunden werden, um diese Bildinformationen verarbeiten zu können. Außerdem sind Verfahren der Vorverarbeitung, Analyse und Extraktion notwendig, um aus diesen Informationen intelligente und automatisierte Verfahren und Systeme entwickeln zu können.
In den letzten dreißig Jahren haben sich die Verfahren im Bereich des maschinellen Sehens immens weiterentwickelt. Besonders Verfahren zur Erkennung von Objekten, die eine Beschreibung, eine Vermessung, Lagebestimmung und Klassifizierung vornehmen, werden häufig eingesetzt, um Entscheidungen für automatisierte Prozesse zu bestimmen. Aber auch das tatsächliche Verstehen und Deuten von Bildinhalten und ganzen Bildszenen hat sich in diesem Bereich sehr stark weiterentwickelt

Allgemein werden Verfahren des maschinellen Sehens sehr erfolgreich im industriellen Umfeld eingesetzt. Besonders zur Kontrolle von Produkten und ganzen Prozessabläufen werden zahlreiche Methoden der Bildverarbeitung eingesetzt. Diese rasante Entwicklung im industriellen Bereich hat dazu beigetragen, dass ganze Forschungszweige an neuen Lösungen und Erweiterungen visueller Verfahren entwickeln und diese bereits erfolgreich in ihre Produkte integrieren. Die größte Schwierigkeit stellt der Einsatz von solchen Verfahren in natürlichen Umgebungen dar. Viele Verfahren sind für den Einsatz in industriellen Umgebungen entwickelt worden, in denen die Umgebung eigens für das Verfahren angepasst und einer ständigen Kontrolle unterzogen wird. Dies führte gerade im letzten Jahrzehnt zu einem Umdenken bei der Entwicklung solcher Verfahren und ganzer Systeme. Besonders im Bereich der Automobilindustrie werden viele Verfahren für das sichere Fahren in natürlichen Umgebungen wie dem Straßenverkehr weiterentwickelt und mit Hinblick auf das autonome Fahren stets verbessert.
Insgesamt decken die Verfahren des Tracking, Objekterkennung, Odometrie und Lagebestimmung sowie der Augmented Reality die zurzeit aktivisten Bereiche des maschinellen Sehens in der Industrie und Forschung dar.
Visuelle Ortsbestimmung, Aktivitäts- und Kontexterkennung
Speziell Positionsverfahren, die visuelle Daten aus optischen Sensoren wie einer Kamera verwenden, sind in den letzten Jahren sehr populär geworden. Optische Sensoren sind günstig zu produzieren und bereits in vielen mobilen Geräten, wie z.B. Smartphones und Tablets, verbaut. Das ist mit ein Grund, weshalb sie für Aufgaben der Lokalisierung und Navigation in kleinen Robotern, Drohnen (Micro Aerial Vehicle) oder auch im Kontext mit Menschen bereits heute eingesetzt werden.
Visuelle Verfahren, speziell aus dem Bereich der visuellen Odometrie, haben den Vorteil ohne jegliche künstliche Infrastruktur zu funktionieren. Ein Nachteil bei klassischen visuellen Positionierungssystemen, die auf Basis von Bildvergleichen zwischen der aktuellen Kameraaufnahme und einer Menge von Standortbildern den Standort eines Nutzers bestimmen, stellt die Standortbilder-Datenbank dar. Hierfür müssen zahlreiche und aktuelle Standortbilder erzeugt und eingepflegt werden, um eine genaue Positionierung für ein großes Areal bereitzustellen.
Dagegen benötigen Verfahren aus dem Bereich der visuellen Odometrie keinerlei Datenbank oder Vorwissen über einen zu lokalisierenden Bereich, um eine erfolgreiche Positionierung durchzuführen. Anhand von visuellen Features können Verfahren der visuellen Odometrie die Eigenbewegung der Kamera bestimmen, um daraus anschließend die eigene Position zu berechnen. Erste Ansätze der visuellen Odometrie haben ihren Ursprung im Bereich der Raumfahrttechnik. Speziell für die Mond- und Mars-Rover wurden solche visuellen Verfahren entwickelt. Verfahren wie die satellitengestützte Positionierung und Navigation sind wegen fehlender Satelliten auf Mond oder Mars nicht möglich. Ebenfalls ist eine Positionierung mittels klassischer Odometrie basierend auf dem Antriebssystem zu ungenau, da die Beschaffenheit der Mond- und Marsoberfläche zu sandig und staubig ist. Mittlerweile werden solche Verfahren auch unter irdischen Bedingungen verwendet, um bewegliche Objekte oder einzelne Personen zu positionieren und zu navigieren.
Durch die Einführung einer neuen Geräteklasse, der sogenannten Wearables, wie z.B. der Google Glass oder Microsoft Holo Lens, sind sinnvolle Anwendungsbereiche der visuellen Odometrie entstanden.
Allgemein setzen Verfahren der visuellen Odometrie Bildinformationen einer oder mehrerer Kameras ein. Ziel der visuellen Odometrie ist es, die Eigenbewegung allein aus einer Sequenz von aufeinanderfolgenden Kamerabildern abzuschätzen.
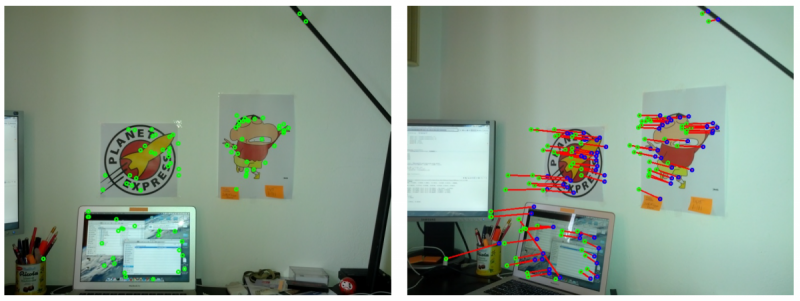
Relative Veränderung von Features zwischen zwei aufeinanderfolgenden Bildpaaren
Im Rahmen der Promotion von Chadly Marouane wurden gemeinsam mit der Virality GmbH und Ludwig-Maximilians-Universität visuelle Verfahren zur Ortsbestimmung, Aktivitäts- und Kontexterkennung auf Basis der Grundlagen der visuellen Odometrie und des maschinellen Sehens entwickelt. Dabei wurden ein visueller Kompass, ein visueller Schrittzähler sowie ein Verfahren zur Aktivitäts- und Kontexterkennung entwickelt, die alle auf Basis von visuellen Feature-Veränderungen innerhalb von Videosequenzen aufsetzen.
Visueller Schrittzähler und Kompass
Anders als bei den klassischen Verfahren der visuellen Odometrie wird ein visueller Schrittzähler und ein visueller Kompass eingesetzt. Dabei unterscheidet sich die hier entwickelte Methode dadurch, dass die Features nicht zur Rekonstruktion von 3D-Koordinaten verwendet werden, um daraus eine Bewegung abzuleiten und zu messen, sondern ausschließlich zur Bestimmung der gegangenen Schritte und Bewegungsrichtungen. Das heißt, dass eine Trajektorie durch die gegangenen Schritte und die Bewegungsrichtung bestimmt wird. Als Eingabe verwenden der Schrittzähler und der Kompass eine vorverarbeitete Videosequenz. Die Videosequenz wird mit Hilfe einer Kamera, die aus der Ego-Perspektive einer Person aufzeichnet, erstellt.
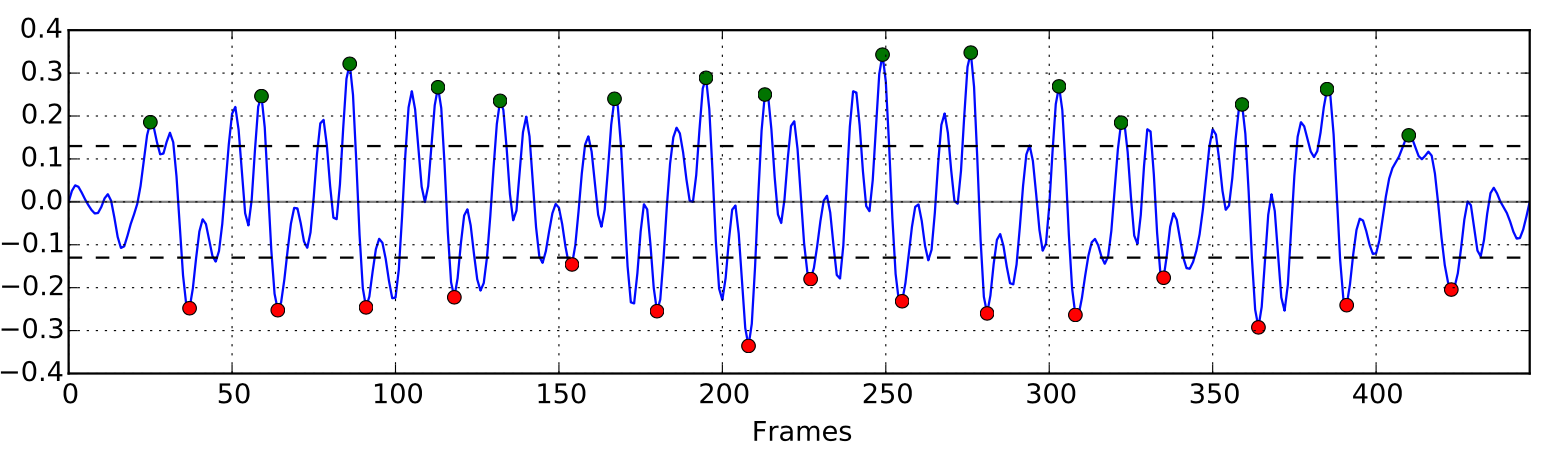
30 gegangene Schritte: Relative Veränderung von Features innerhalb einer Videosequenz aufgezeichnet aus der Ego-Perspektive
Anhand der relativen Feature-Veränderungen zwischen zwei aufeinanderfolgenden Bildern innerhalb einer solchen Videosequenz lassen sich markante Muster erkennen. Diese werden zur Ableitung von gegangen Schritten herangezogen. Dabei werden die Schritte anhand der relativen Kontrastveränderungen zwischen zwei Feature-Paaren erkannt. Solche Kontrastveränderungen lassen sich mit einem Glanzpunkt auf einer Glasfläche vergleichen. Bewegt man sich auf diesen Glanzpunkt zu, pendelt dieser mit jedem Schritt entweder nach links oder rechts. Durch diese Eigenschaft lassen sich einzelne Schritte erkennen und sich sogar auf den linken oder rechten Fuß eingrenzen.
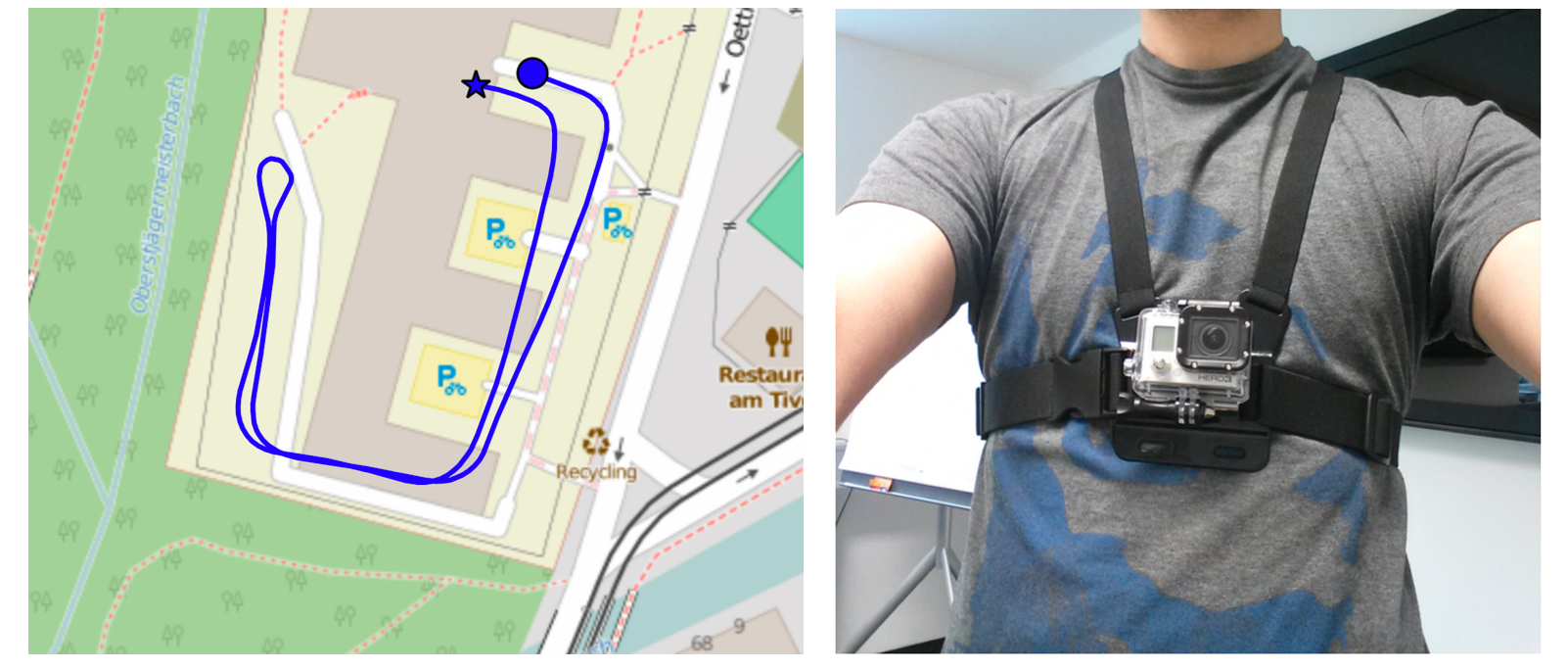
(links) Rekonstruierte Trajektorie anhand des visuellen Schrittzählers und Kompass – (rechts) Versuchsperson mit einer Body-Mount Kamera (GoPro Hero Wifi)
Um die Verweildauer an einer aktuellen Position zu bestimmen, wird jeweils die Schrittfrequenz verwendet. Somit lassen sich schnell abgelaufene Pfadabschnitte bestimmen und deutlich von langsam gegangenen Pfadabschnitten und Stillstands Phasen unterscheiden.
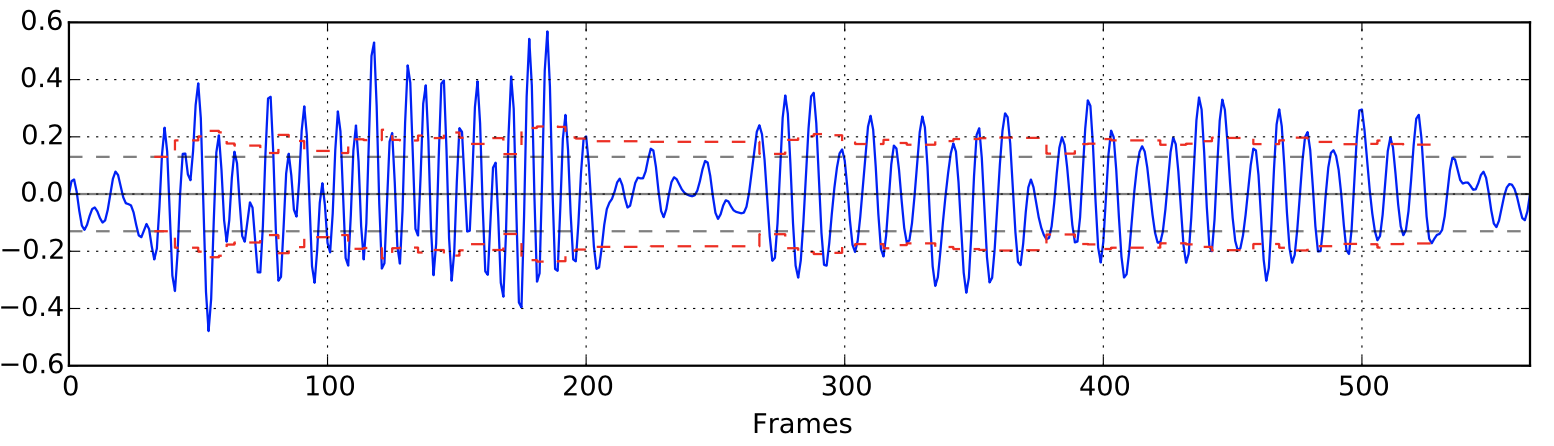
Darstellung unterschiedlicher Schrittgeschwindigkeiten – Laufphase, Gehphase und Stehphase
Visuelle Aktivitäts- und Kontexterkennung
Leider ist die Schrittfrequenz nicht immer ein guter Indikator zur Bestimmung einer Aktivität oder gar zur Erkennung eines Kontextes. Daher wurde ein Verfahren entwickelt, dass auf Basis aller Attribute eines Feature-Paares reagiert. Hierfür wurden Verfahren des maschinellen Lernens verwendet, die auf Basis von Trainingsdaten geeignete Klassifikatoren entwickeln. Diese wurden verwendet, um aus einer unbekannten Videosequenz Aktivitäten zu erkennen.
Nicht jede Aktivität kann durch einen Klassifikator zu 100 % erkannt werden. Jedoch wurde bereits im vorherigen Abschnitt gezeigt, dass sich klassische Aktivitäten, wie das Laufen, Gehen und Stehen, bereits einfach anhand des Schrittzählers und der Schrittfrequenz unterscheiden lassen. Neben diesen klassischen Aktivitäten sollen Aktivitäten wie das Treppensteigen, Kurven gehen oder auf der Stelle drehen ebenfalls erkannt werden. Auch Kontexte lassen sich dadurch anhand eines Klassifikators relativ einfach unterscheiden. Besonders große Menschenmengen, wie man sie auf Großevents antrifft, Altstädte, dir durch ihre markanten Fassaden und engen Gassen auffallen, sowie Park- und Freizeitanlagen lassen auf bestimmte Kontexte zurück schließen, wie z.B. Festivalbesuche, Urlaubsbesuche oder Sportaktivitäten.
Das hier vorgestellte Verfahren beschränkt sich jedoch zunächst nur auf die Erkennung von Aktivitäten, wie z.B. Gehen, Stehen, Laufen, Kurven gehen, Treppensteigen, etc.:

Klassifizierung von Aktivitäten – (von oben nach unten) die ersten drei Graphen stellen unterschiedliche Ausprägungen der Feature-Attirbute dar, der letzter Graph stellt die Ergebnisse des Klassifikators (erkannte Aktivitäten) dar.
Die unterschiedlichen Ausprägungen der Attribute eines Feature-Paares eignen sich sehr gut zur klaren Unterscheidung unterschiedlicher Aktivitäten. Dabei sind bereits kurze Videosequenzen (ca. 3 min.) ausreichend um geeignete Trainingsdaten zu erhalten, die zur Entwicklung eines ausreichend guten Klassifkators verwendet werden können.
Fazit
Die vorgestellten Verfahren sind noch in einem frühen Stadium der Reife und sind daher noch verbesserungsfähig. Insgesamt lassen sich jedoch die vorgestellten Verfahren sinnvoll kombinieren und einsetzen. Sie bieten die Möglichkeit, allein anhand von visuellen Informationen eine Lage- und Positionsbestimmung sowie eine Aktivitätserkennung zur Verfügung zu stellen.
Es bleibt weiterhin interessant, wie sich visuelle Verfahren zukünftig bemerkbar machen und eingesetzt werden. Schon heute gibt es zahlreiche Beispiele für den erfolgreichen Einsatz visueller Verfahren in unserem Alltag.
So werden zahlreiche Kamerasensoren und visuelle Verfahren in moderne Automobile eingesetzt, um Teilbereiche des Fahrens autonom und sicher zu gestalten. Auch der Erfolg von Head-Mounted Displays, wie z.B. der Oculus Rift und der HTC Vive, gibt den visuellen Verfahren eine immer größer werdende Bedeutung. Die Displays werden in erster Linie zum Abbilden virtueller Welten eingesetzt, jedoch wechselt der Fokus immer mehr auf das Erweitern unserer Realität durch virtuelle Objekte. Hierfür benötigt man robuste Verfahren, die die Eigenbewegung, die Position und den aktuellen Ort sowie den vollständigen Kontext ermitteln können, um möglichst realitätsgetreu virtuelle Objekte in unsere Realität zu integrieren. Die vorgestellten visuellen Verfahren können dazu beitragen, diese Systeme zu unterstützten und zu erweitern. Jedoch werden auch diese visuellen Verfahren an ihre Grenzen kommen und nicht allein ausreichen um diese Anforderungen vollständig zu erfüllen. Trotz dieser Möglichkeiten, die visuelle Sensoren und visuelle Verfahren mit sich bringen, ist ein robustes Verfahren und System erst durch den Einsatz unterschiedlicher Sensoren geben. Daher kann nur durch eine Informationsfusion, welche Daten aus unterschiedlichen Sensoren vereint, eine präzise Aussage über die Position, Aktivität und den Kontext einer Person geben werden.